Conscious Decoupling: Separating Budgets For Thought and Action

Current LLM services bundle model intelligence with supporting infrastructure into fixed tiers. When you purchase access to GPT‑5 Thinking, Claude Opus 4.1, or similar offerings, you receive a package: some amount of model capability paired with some unspecified quantity of supporting compute. This bundling serves a purpose. It simplifies the interface and provides a working system out of the box. But it hides consequential levers for capability, quality, and speed. For instance, to improve quality, it may be useful to run multiple generations and select or synthesize the best. For speed and quality, it may be useful to have these generations run in parallel. Or it may help to run evaluation, search, and data processing in parallel across several machines, or choose larger machines that can execute broader analyses within the same wall‑clock time. All of these cost money and it may be fine to ask users for their preference (you could think of it is a prompt for size and scale) or let users pick specific things and let them learn what works best for their problem. For instance, we could let users specify that the system search widely but draft briefly or run a few experiments before writing or spend the bulk of the budget on checking and improving what was written.
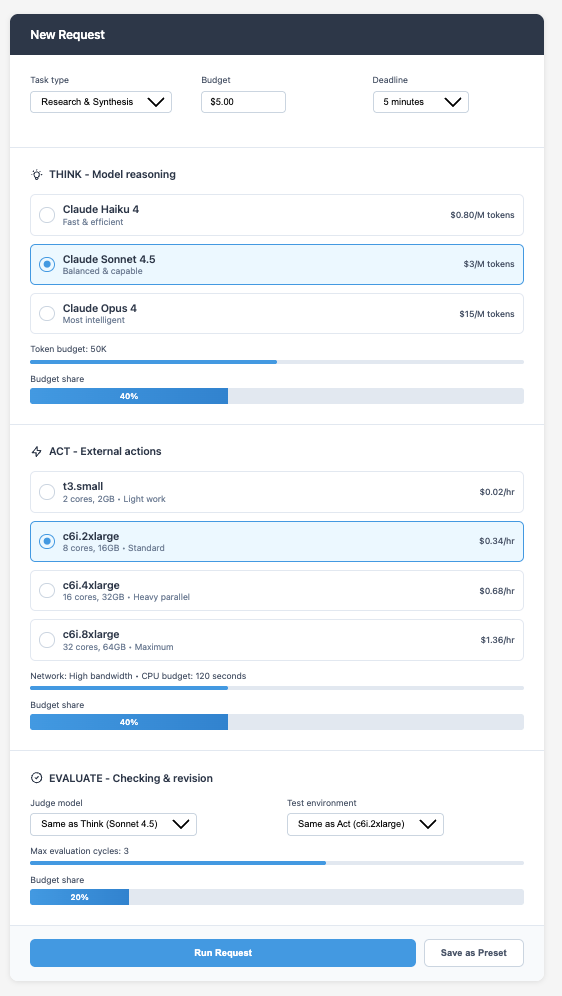
One way to design the system is to treat the user’s request as a policy and the runtime’s response as a plan. Policy is short and human: objectives, limits, and preferences. For example, produce one best answer, bias toward exploration over polish, and cap both cost and latency. The plan is the execution the system derives from that policy: how many candidates to try, which tools to call, how to split spend between internal reasoning and external actions, how many evaluation cycles to run, and when to stop.
A small decomposition keeps the interface clear and maps to hardware.
- Think is internal model work such as planning, drafting, and synthesis. It mainly consumes tokens on accelerators.
- Act is everything outside the model: retrieval, browsing, API calls, script execution, and small experiments. It mainly consumes CPU, I/O, and network. Reading fits here because it interacts with the world rather than synthesizing text.
- Evaluate is analysis of outputs: self-critique, static checks, test runs, citation verification, reranking, and edits guided by those checks. It draws on both sides. Some checks use a judge model and spend tokens; others are tool- or test-driven and spend CPU.
The mapping is an approximation rather than a rule, but it is accurate enough to make budgets legible and to separate GPU-style spend from CPU-style spend.
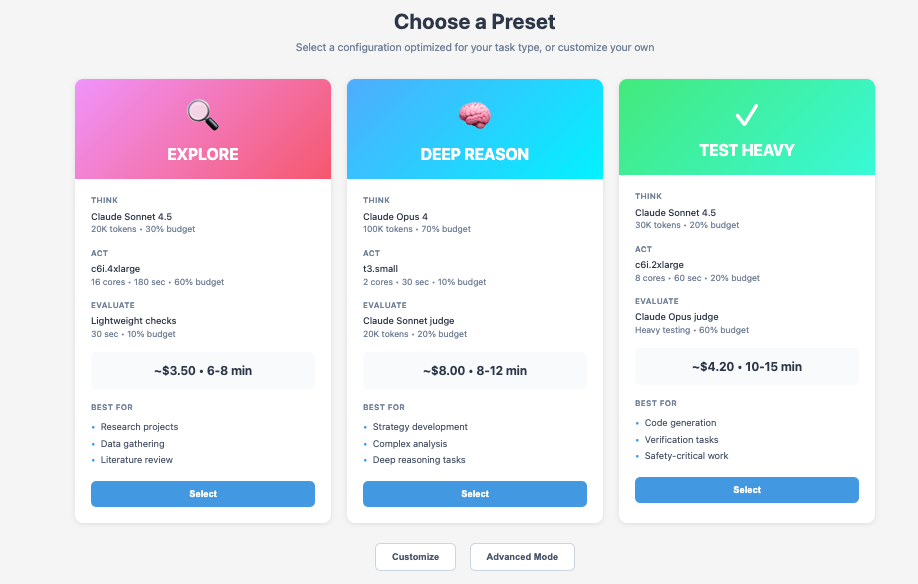
With this in place, a request needs only a few fields. The user sets a macro budget and a soft deadline, states an output intent such as one answer or a few diverse options, and gives a split preference across Think, Act, and Evaluate. The split can be a simple ratio or a preset such as Explore-heavy, Evaluate-heavy, or Balanced. The runtime turns that policy into a plan. It allocates tokens for reasoning and any judge-model passes, CPU and network for external actions, and a bounded number of evaluation cycles. Execution is multi-turn by default: draft to frame options, act to gather evidence or run a quick experiment, evaluate and edit, and repeat while the expected value of another cycle justifies the remaining spend. The output need not be final on the first attempt.
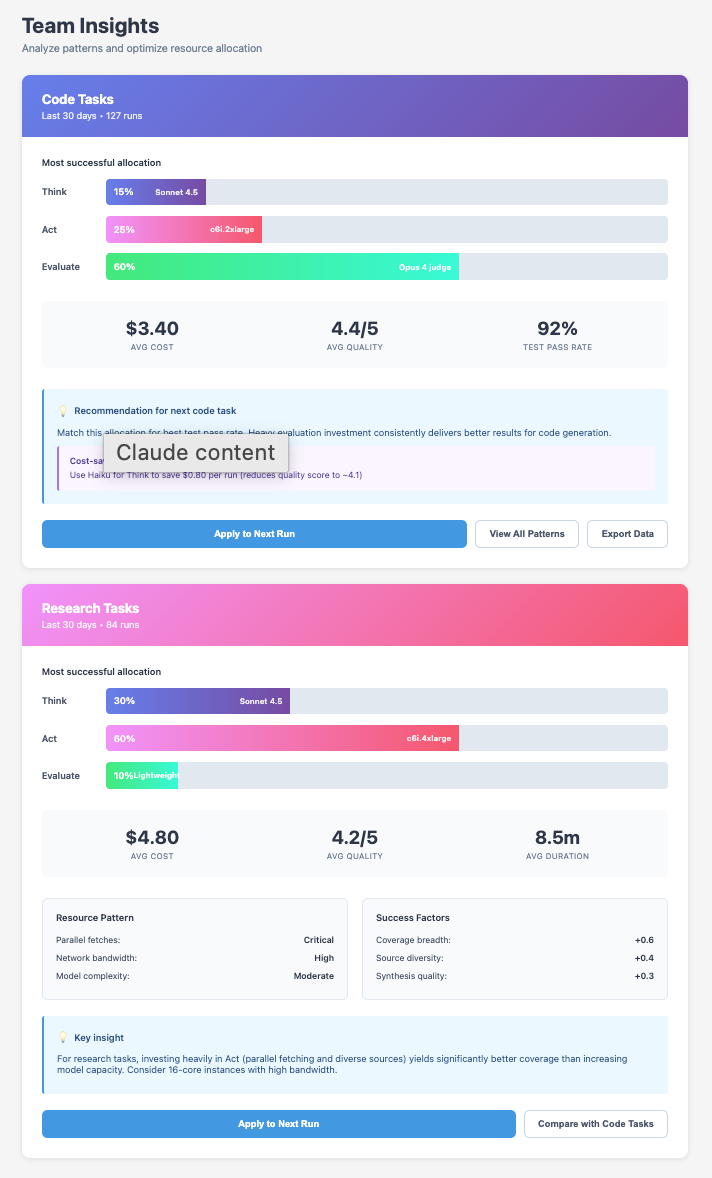
Two mechanics keep this predictable. The system uses checkpoints because token totals and fetch sizes are uncertain. Before each phase it estimates the remaining budget and either continues, rebalances, or stops if projections would breach the limit or the deadline. It also returns clear telemetry: tokens used for reasoning and for judging, counts of external requests, CPU seconds, egress, latency, and the number of evaluation cycles. That record lets teams price workflows, compare presets, and understand which levers moved quality.
This control surface is not only a way to steer a single run. It is also an instrument for learning how much compute different problems warrant. Each run yields a small dataset: the task tag or description, the Think–Act–Evaluate allocation, realized spend, and an outcome signal. Outcome can be explicit user feedback, agreement among independent runs, test pass rates, or correction volume on a second pass. From these records the system can fit simple spend-versus-quality curves by task family and by phase. Code synthesis often improves when a larger share goes to evaluation and tests. Literature reviews often improve when a larger share goes to action and breadth. The curves will be noisy, but even coarse patterns help.
These patterns support grounded defaults rather than guesswork. Before a request runs, the planner can propose an allocation that usually meets a target quality and cost for similar tasks, along with an honest range. The user can accept or adjust. The plan still respects the budget and deadline and still stops when another cycle is unlikely to change the ranking of candidates. The point is not to dictate an aggressive or conservative stance. It is to make the trade-offs explicit and to base defaults on observed outcomes. If errors are costly, heavier evaluation will tend to dominate. If exploration is cheap and variety is valuable, breadth will tend to dominate.
The controls can be minimal and still useful.
- Model selection. Choose a model tier for drafting, judging, and evaluation.
- Infrastructure tier. Choose a light, standard, or heavy environment, or a degree of parallelism for external actions.
- Budget split. Allocate the fraction of spend for model work and for infrastructure, either as percentages or via presets such as Explore-heavy, Balanced, or Reason-heavy.
From these inputs, the runtime constructs a plan, executes in cycles with checkpoints, and reports where money and time went. If infrastructure dominates, the task is infrastructure-bound. If tokens dominate, it is model-bound. That guidance improves the next run: increase parallel gathering, allocate more model tokens for deeper synthesis, or shift spend to evaluation if quality hinges on tests.
Sample Interfaces