Cell Mates: Extracting Useful Information From Tables for LLMs
We seem to have cracked the art of distilling information in words and images using large machine learning models. However, our ability to exploit useful information in tabular data using large models is mostly missing. The upshot is that LLMs don't largely encode the knowledge from these tabular datasets, e.g., survey data, etc., outside of the statistical summaries that may have been published. The key hurdle in incorporating tabular data is coming up with a useful representation. Representing tables as a set of documents, with each row represented as a sentence, will miss most of the knowledge inside a table. And doing it naively may be worse than useless. For instance, not knowing that data is in long form may mean repeating correlated data endlessly.
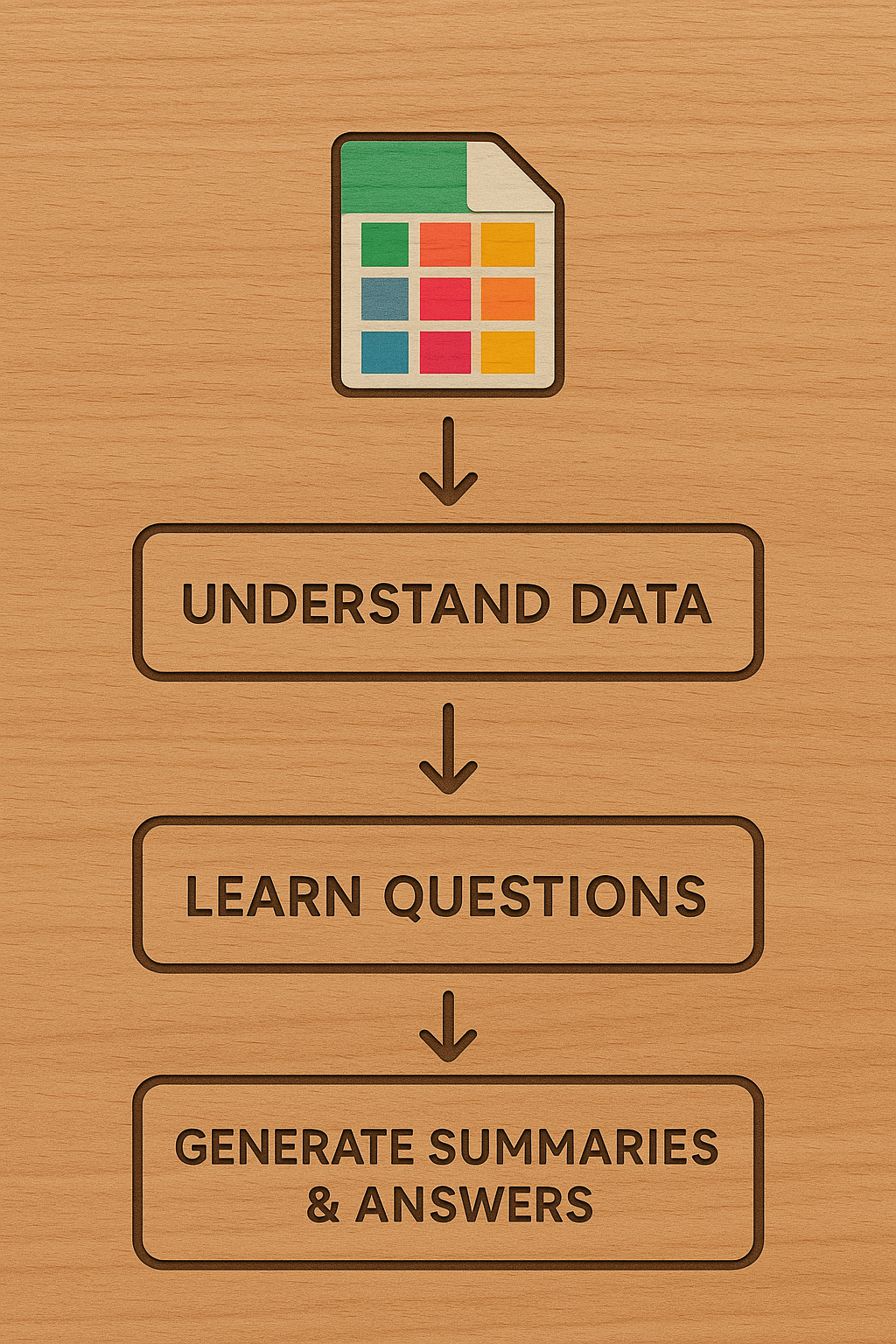
A better proposition may be to rely on mechanical distillation techniques: create univariate, bivariate, and some multivariate summaries based on the best guess about the table structure, e.g., long-form table, etc., which may sometimes be available in data dictionaries. We could augment these further by prompting the LLM to propose the kinds of questions that we could pose to the data and learn from it. In all, there are three steps to such a pipeline:
- Understand the data, e.g., how it was collected, how it is structured, etc.
- Learn what kinds of questions can be asked of the data,
- Create mechanical summaries, e.g., means, correlations, group bys, etc., and answers to #2, along with details about what was precisely done to create those answers. Also, produce plots.
Here's an initial attempt. As always, we would need some ground-truth data to validate how well this works. But as always, we would also need a dash of humility. Even a system that understands the data perfectly, produces good questions, and produces excellent summaries will produce an incomplete set. The total number of questions that can be asked of any data is potentially infinite.
We could use this pipeline for RAGs and for supplementing 'world data', which is plausibly biased toward striking findings. Data repositories for scientific papers, such as those found on the Harvard Dataverse and administrative data, are excellent places to get started.
p.s. The point extends beyond tabular data. Data sitting in JSON objects, etc., is all underutilized.